Failover tests
This page should describe the operations executed using BackgroundOperationsManager, started/stopped using BackgroundStressors(Start/Stop)Stage and checked using BackgroundStressorsCheckStage. Other stages used during failover testing such as Service(Start/Stop) stage or WaitForTopologyTopology(Event/Settle)Stage won’t be described, these are more or less trivial, refer to their documentation.
BackgroundStressorLogic and LogValues
Initially we have used tactics known now as BackgroundStressorLogic: we spawn several threads issuing a put/get operation every 100 ms (check property thinkTime scoped into GeneralConfiguration) - those threads are not terminated after the end of the stage but kept working on the background. There are another threads to retrieve and record statistics. In order to check whether the cache has all entries, we have used CheckCacheDataStage.
This approach works for checking the lag of response times, see how the throughput drops when one node crashes etc. That makes use of this ‘BackgroundStressorLogic’ valid for cases, where we want to check the performance during failover.
However, it’s not a good functional test: the stressors mindlessly overwrite all the entries (not firing any alarm if the entry is lost) and by the time CheckCacheDataStage runs, the entry can be already loaded again. Even if those checks were in place, only really missing entries would be detected; but there’s much more that can go wrong: not applied writes, double writes, inconsistencies and so on.
That’s why ‘log values logic’ was devised. This is activated by setting property log-logic-enabled to true. It is similar to BackgroundStressorLogic in some ways: we start some threads and let them run on the background. Then we run another stages, restarting the nodes and whatever we like, but every while we insert the BackgroundStressorsCheckStage: this has very low overhead, it just checks whether some error was detected and fails the benchmark if it was.
It’s important to note that the implementation of log checkers was developed and tested only on Infinispan. There can be subtle oddities for example in the transactions behaviour (ACID? LOL!) that were already fixed but there could be false positives for other caches/grids.
The principle of log logic is quite simple: we don’t use opaque fixed-size values as in BackgroundStressorLogic (where performance is the top priority) but the values are append-only lists. There are two types of threads: stressor threads, which have deterministic sequence of accessing the entries, and during each operation append operationId to the value (reading the value first, appending operationId locally and writing the entry again). Then there are checker threads, which know the sequence of stressors and follow them, checking that each operation was correctly appended.
Above I have written that we always append to the value. How do we test removes, then? In fact, for each logical key there are two entries: under key ‘key_0000000000001234’ and ‘key_FFFFFFFFFFFFEDCB’ - see, the binary complement of the number. When we want to execute remove, we append operationId to the value and write it under the complementary key. Then we can safely remove the value under primary key.
The stressors don’t keep any data about their entries in memory but the sequence seed and current operationId. When they want to execute operation on given key, they have to load the entry first. Therefore, if the remove was not executed (we would read the old value), we would continue without the operationId that ‘removed’ the entry and checkers would soon detect that.
By default there are 10 stressor threads on each node. The checkers on one node have to check all stressors from all nodes in order to guarantee that each node has correct view of the data. However, we don’t keep a checker for any stressor on each node: instead, just the expected state of those stressors are kept and we have a pool of checkers which check those stressors.
The checkers must know what was the last operation of any stressor (otherwise, if the checker was faster, it would report missing operations because the stressor did not managed to execute it so far). All communication happens through cache: the stressor regularly writes its last operationId and seed for the deterministic sequence under a special key. This entry is also read by the stressor after the node where the stressor resides is restarted, so that it know where to begin from.
If we executed the test for long enough, the log values would grow without bounds. That’s why each checker stores the last checked operation in the cache - if stressor finds out that the entry has grown too big, it finds the highest operationId that was already checked on all nodes and truncates operationIds up to this value. The checkers also use their last checked record when the node is restarted.
There’s one more option ignoreDeadCheckers that can be useful for elasticity tests: if the cluster shrinks to single node, the stressors on one node cannot progress as the local writes are fast, the checkers on dead nodes cannot follow and the entry grows to max size soon. That’s why the stressor may decide to truncate entries that were not checked, but records this under special key so that the checkers that are spawned after the other nodes start again don’t panic.
If property sharedKeys is set to false (this is the default), each stressor thread operates on its private set of keys. Basic operations (put, get, remove) are enough for that. However, when you set sharedKeys to true, all stressors update the same set concurrently. Here we need the conditional operations such as putIfAbsent, conditional replace and conditional remove. Also, the entry value (aka log value) has to keep stressorId along with each operationId.
Private log logic
This is the simplest mode: the stressor retrieves primary value, and if it is null, it retrieves complementary key. Then it writes the new value (either overwriting the primary key or backing up to complementary entry) and then removes the other entry.
The checker tries to retrieve primary value, and if it is null, retrieves the complementary one. There’s a chance that the stressor managed to ‘move’ the value between those two gets, therefore, the checker tries the process above 100 times to make sure the value was really lost. When it manages to retrieve some value, it must contain the operationId (it doesn’t matter whether this is the older or newer one).
Shared log logic
The stressor has to always retrieve both values (primary and complementary), and the new value is union of those two with the operationId appended. That’s because we cannot update those two values atomically (without transactions), we have to deal with the fact that concurrent operations may fails.
Later it tries to write the new value under appropriate key: however it has to use conditional operation to make sure that the entry was not overwritten after the old value was retrieved. If this conditional operation fails, we have to start from the beginning (just for this operation, naturally). The removal of the other entry is also conditional, but if this one fails, we don’t repeat the operation - another thread has probably again moved the value.
The checker has to cope with that: it tries to find the operationId for 100 times from either primary or complementary entry. When it is not successful after that many attempts, error is recorded.
Transactions
The basic difference is simple: we just execute begin() and commit() every few operations. If the commit fails, we have to start from the beginning of the transaction - we have to be able to rollback the stressor seed to this moment.
However, there’s one unexpected behaviour of Infinispan: reading two values (even within transaction) that are modified inside single transaction can retrieve one value before the transaction and second after that. Multiple writes are not atomic with respect to reads.
That means, that we have to:
- write the last stressor operation in separate transaction (after the transaction whose operations we are confirming is committed)
- separate updates/inserts and removes to two transactions, execute updates first and removes only after that (otherwise, we could see the remove before insert, and the value would appear to be lost for a while)
- we also have to make sure that when we separate the updates this way, we don’t keep remove for both primary and complementary value in one transaction (that way we would remove the value instead of just moving it): only the last remove can win
Clustered listeners
Clustered listeners is quite a new feature, and support in RG was not thoroughly tested yet. However, the implementation is quite simple: we register clustered listener for every operation and then record those operations to the same record as regular confirmation from the checker thread. Then, check for this stressor cannot follow until the notification is receiver as well as the value through regular get.
Component overview
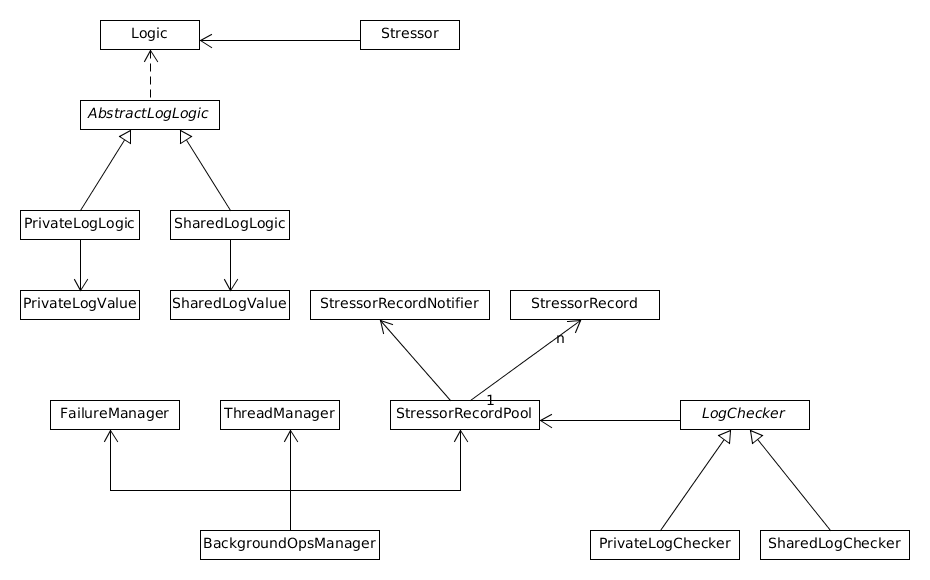
- BackgroundOpsManager (BOM) - core component responsible for managing and orchestrating test run. BOM is is able to survive service restarts, as it is stored in worker state. Additionally, it is able to react to service restarts by automatically starting/stopping threads (by implementing ServiceListener). Its logic is delegated to separate classes:
- FailureManager - responsible for keeping track of failures that occurred during test run (missing operations, missing notifications, stale reads, failed transaction attempts, delayed remove errors)
- ThreadManager - manages all stressor and checker threads (start/stop/wait). Starts KeepAliveTask, which regularly inserts a value containing worker index and current timestamp. Some tests use it to determine whether node is dead.
- StressorRecordPool - FIFO structure (queue) containing StressorRecords.
- StressorRecord - records are used by checker threads to keep track of latest key checks. Generally speaking, they contain current key id, operation id, latest successful/unsuccessful check timestamps that enable us (BackgroundStressorsCheckStage) to determine whether we make any progress. It is important to note that StressorRecords are created with respect to number of stressors and their key ranges. For illustration, consider an example with 4 nodes, 10 stressors per node and 10000 keys. Total of 40 StressorRecords will be created, with first one having key range of 0-249, second one 250-499, etc. At the same time, stressor 0 on node 0 will have range 0-249, stressor 0 on node 1 will have range 1000-1249, etc. This way checkers can also check writes performed by stressors on different nodes. A StressorRecord can be checked only by one checker thread at the same time, after the checker finishes, it returns the record back to the pool. This guarantees fairness of checking process. StressorRecords also maintain list of confirmations, which are added at some points of the test (will be discussed later) to mark latest operations (see Last operation key), which have been written for given record.
- LogChecker - Abstract superclass for checker implementations (PrivateLogChecker, SharedLogChecker). It runs generic checking algorithm in a loop, individual subclasses provide way to retrieve current value from StressorRecord and to verify whether the value contains currently checked operation.
Checking algorithm (general)
- Take record (queue head) from StressorRecordPool
- If last unsuccessful timestamp is set, add record confirmation (Last operation key) to mark the operation that we’re sure is written into the cache
- Find value for given record - get operation(s) will be performed on a cache, where key is obtained via StressorRecord.getKeyId
- Check whether current operation can be found in the value from step #3
- True - set record timestamps (successful to current time, unsuccessful to undefined), remove all confirmations with operationId <= record.currentOperationId, generate new key for given record, increment operation id
- False - check whether confirmations contain operation with operationId > currentOperation
- If not, check whether operation for given stressor shouldn’t be ignored (see Ignored key)
- If not, record missing operation in FailureManager
- Set record timestamp (unsuccessful to current time, remove all confirmations with operationId <= record.currentOperationId, generate new key for given record, increment operation id
- Return record back to StressorRecordPool
Data written into cache during test
Checker
- Checker key (checker_$workerId_$stressorId) - written by checkers every logLogicConfiguration.counterUpdatePeriod operations, it denotes how far a checker has been able to get with checking process (by storing latest operation id for given stressor). When stressor finds out that log value has attained maximum size (logLogicConfiguration.valueMaxSize), it performs a query for all checker keys (cluster-wide) and determines the lowest operation id (LOI). Afterwards, we can safely trim all operation ids <= LOI from the log value.
Stressor
- Entries picked from key range defined by LogLogic implementation
- Last operation key (stressor_$stressorId) - for non-transactional caches we write the latest operation every logLogicConfiguration.counterUpdatePeriod operations, for transactional caches we insert the entry anytime a transaction succeeds. This helps us to see whether an operation is missing (has been lost) in the log value - e.g. if the last confirmed operation is 100 and we cannot find operation with operation.id < 100 in the log value, missing operation is recorded in FailureManager.
- Ignored key (ignored_$workerId_$stressorId) - if maximum size of a log value is attained, we would normally have to wait until checkers confirm some operations to be checked to be able to exclude them from the log value (see Checker key in previous paragraph). With logLogicConfiguration.ignoreDeadCheckers enabled, we can ignore checkers on dead nodes (as they cannot progress) - this can be used in elasticity tests as the cluster often shrinks and majority of original nodes are down. Updated when maximum size of log value is attained and node ($workerId) is not alive.